Site Auditを設定するには、まずドメインのプロジェクトを作成する必要があります。 新しいプロジェクトを作成したら、プロジェクトインターフェースのSite Auditブロックにある [設定] ボタンを選択します。
Site Auditの実行に問題がある場合、Site Auditのトラブルシューティングを参照してください。

ドメインとページの制限
セットアップウィザードの最初の部分、ドメインとページの制限が表示されます。 ここから、「Site Auditを開始」を選択すると、デフォルトの設定ですぐにサイトの診断が行われますし、診断の設定を好みに合わせてカスタマイズすることもできます。 しかし、最初の設定後、いつでも設定を変更して、サイトのより特定の領域をクロールするために診断を再実行できますので、ご安心ください。
クロール範囲
特定のドメイン、サブドメイン、サブフォルダーをクロールするには、「クロール範囲」フィールドに入力します。 このフィールドにドメインを入力すると、チェックボックスでドメインのすべてのサブドメインをクロールするオプションが表示されます。
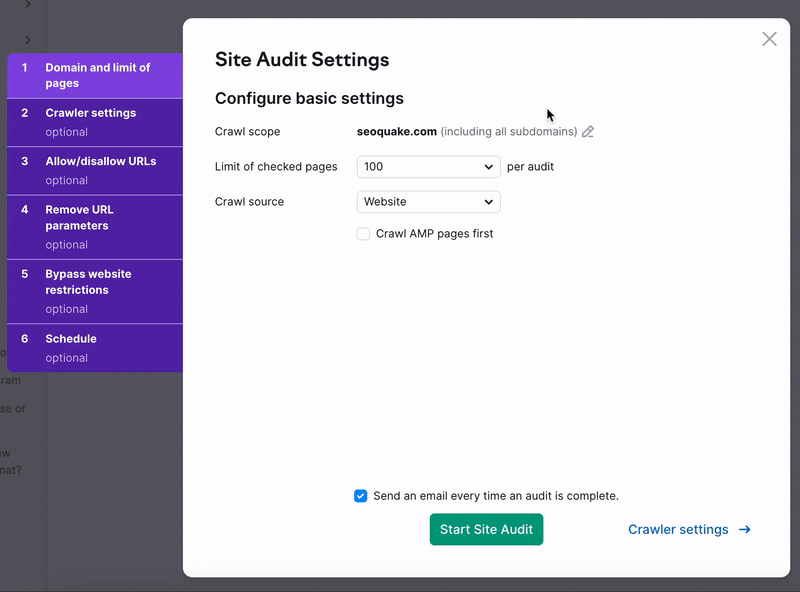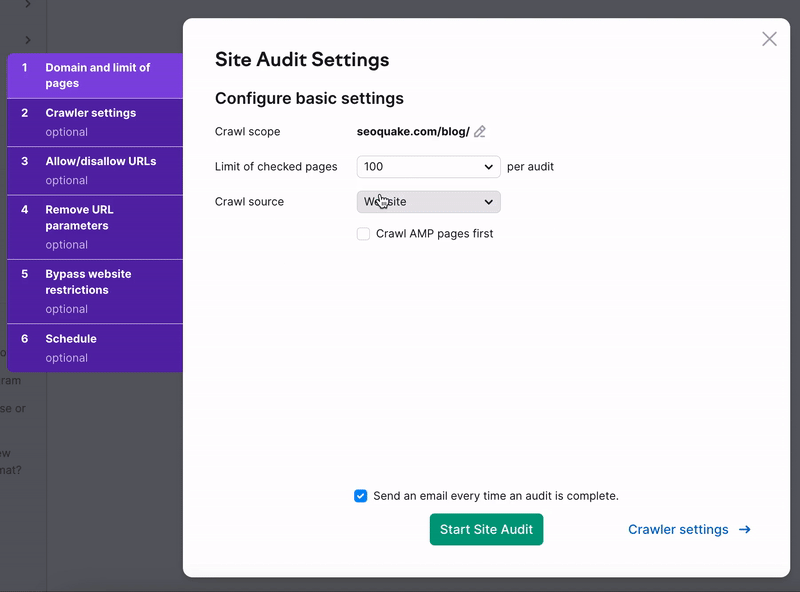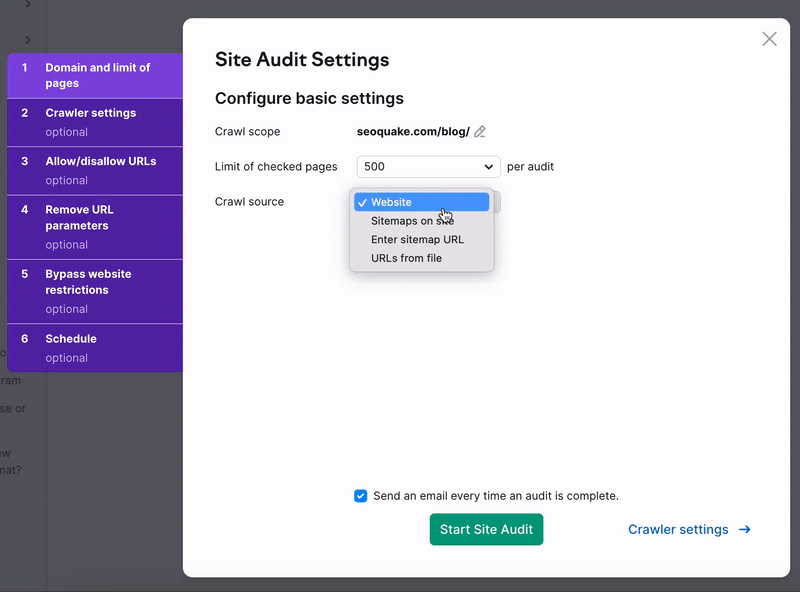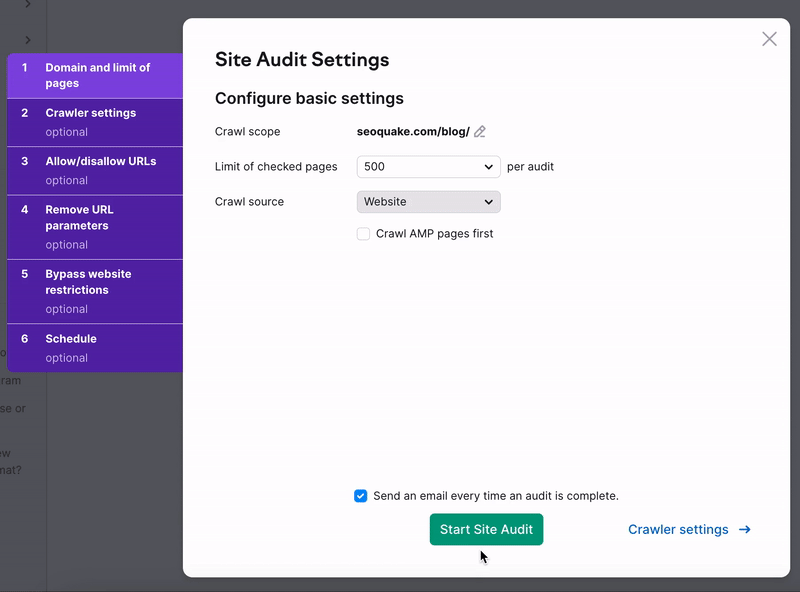
チェックしたページの制限
次に、1回の診断でクロールするページ数を選択します。 「カスタム」オプションを使用して、カスタマイズされた金額を入力できます。 この数値は、お申し込みのレベルやウェブサイトの再診断の頻度に応じて、賢く選択したいと思います。
- Proユーザーの場合、月間10万ページ、1回の診断で2万ページまでクロール可能です。
- Guruユーザーは毎月30万ページ、1回の診断で2万ページをクロールできます。
- Businessユーザーの場合、月間100万ページ、1回の診断で 10万 ページまでクロール可能です。
クロール元
クロール元の設定は、Semrush Site Auditボットがどのようにウェブサイトをクロールし、診断するページを見つけるかを決定します。 クロール元の設定に加えて、セットアップウィザードのステップ3および4で、診断に含める/除外するマスクとパラメータを設定できます。
Auditのクロール元として設定するオプションは4つあります。「ウェブサイト」、「サイトマップ」、「URL別サイトマップ」、「URLのファイル」の4つです。
1. ウェブサイトからのクロールとは、GoogleBotのように、幅優先の検索アルゴリズムを使用して、ホームページから始まるページのコードに表示されるリンクを通じて、お客様のサイトをクロールすることを意味します。
サイトの最も重要なページだけをクロールしたい場合は、「ウェブサイト」からではなく「サイトマップ」からクロールするように選択すると、ホームページから最もアクセスしやすいページだけでなく、最も重要なページも診断対象としてクロールするようになります。
2. サイトマップからサイト内をクロールするは、robots.txtファイルからサイトマップにあるURLのみをクロールすることを意味します。
3. サイトマップからURLでクロールは、「サイト上のサイトマップ」からクロールするのと同じですが、このオプションでは、サイトマップのURLを具体的に入力できます。
検索エンジンはサイトマップを使用して、どのページをクロールすべきかを理解するため、常にサイトマップをできるだけ最新の状態に保つように心がけます。また、正確な診断を受けるために、当社のツールを使用してクロール元として使用する必要があります。
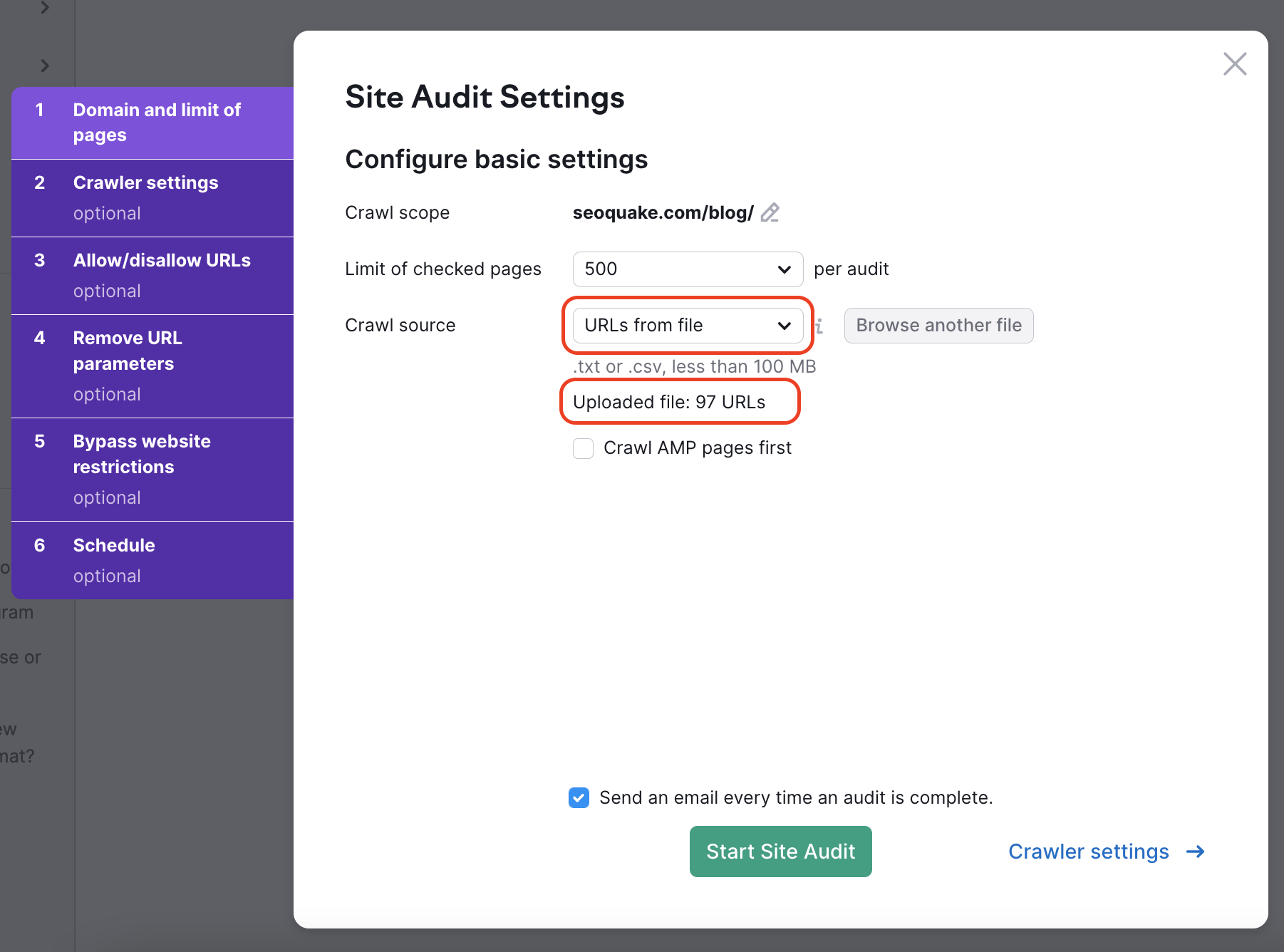
4. URLファイルからのクローリングにより、ウェブサイト上の特定のページグループを診断できます。 ファイルが1行に1つのURLを含む.csvまたは.txtとして適切にフォーマットされていることを確認し、コンピュータからSemrushに直接アップロードします。
これは、特定のページだけをチェックし、クロールの予算を節約したい場合に有効な方法です。 サイト内で確認したい一部のページのみに変更を加えた場合、この方法を使えば、特定の診断を実行できます。こうすることにより、クロールの予算を無駄にすることはありません。
ファイルをアップロードした後、ウィザードは検出されたURLの数を表示するため、診断を実行する前に正しく動作しているかどうかを再確認できます。
JavaScriptのクロール
サイト上でJavaScriptを使用している場合、AJAXクローリング方式を導入すれば、Site AuditはJavaScript内のリンクを発見し、リンク先のサイト上のコンテンツまでフォローします。 キャンペーンを再実行し、クロール元をウェブサイトからサイトマップに変更するだけで問題ありません。 詳しくは、ニュースリリースをご覧ください。
AJAXクローリングにより、JavaScript要素があるページを見つけ出し、そのページのHTMLをクロールし、パフォーマンスチェックでJSやCSS要素のサイズを測定します。
詳細設定と構成
注: 次の4つのステップの設定は高度なものであり、オプションです。
クローラー設定
ここではサイトをクロールするユーザーエージェントを選択できます。 まず、SemrushBotまたはGoogleBotのモバイル版またはデスクトップ版のいずれかを選択し、診断のユーザーエージェントを設定します。
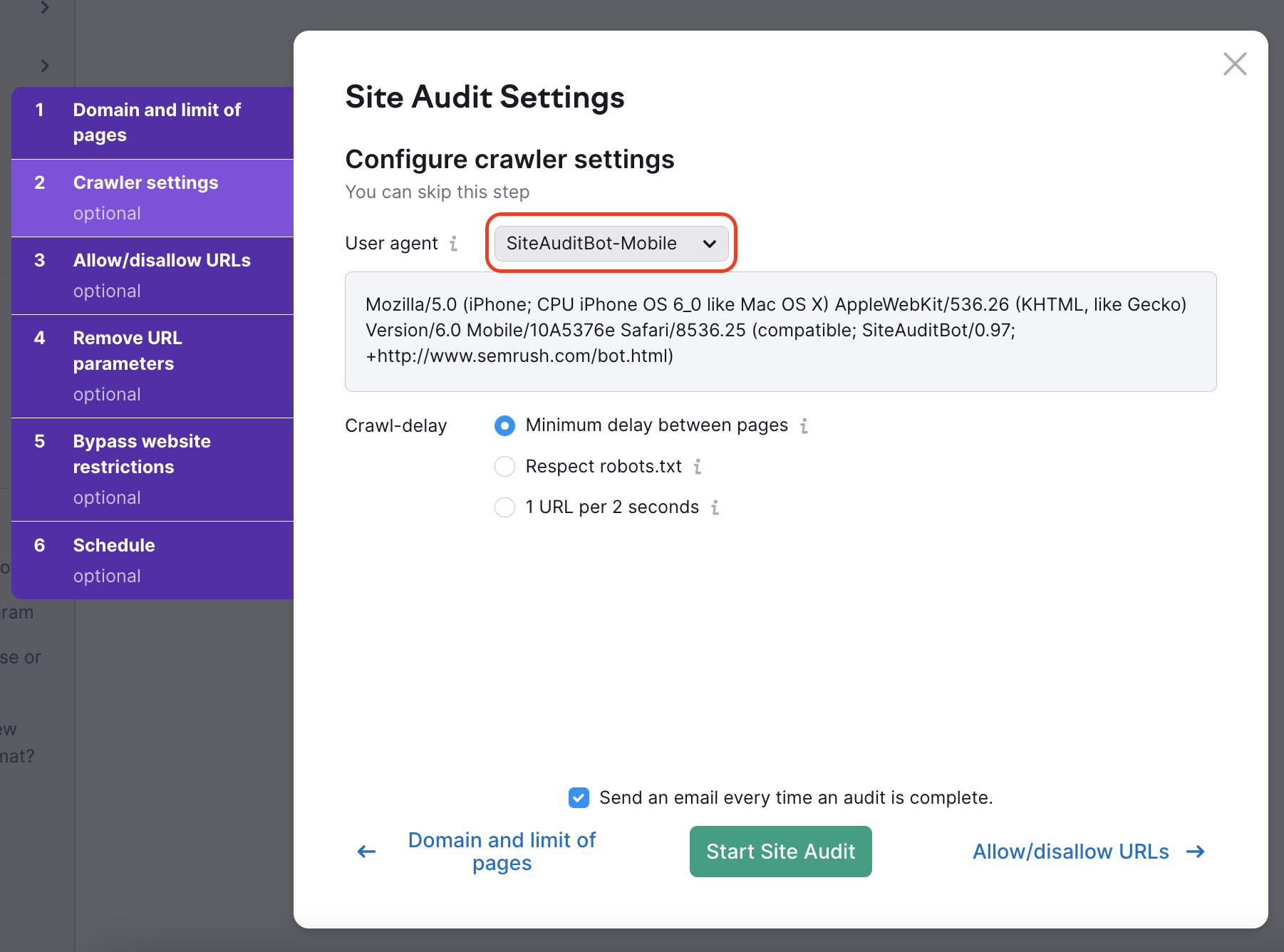
ユーザーエージェントを変更すると、下のダイアログボックスのコードも変更されるのがわかると思います。 これはユーザーエージェントのコードで、ユーザーエージェントを自分でテストしたい場合にcurlで使用できます。
Crawl-Delayオプション
次に、クロールの遅延を設定するための3つのオプションがあります。最小遅延時間、Respect robots.txt、2秒に1個のURLの3つです。
このページ間の最小遅延をチェックしたままにしておくと、ボットは通常の速度でウェブサイトをクロールします。 デフォルトでは、SemrushBotは別のページのクロールを開始する前に約1秒待機します。
robots.txtファイルがサイトにあり、クロール遅延を指定している場合、「respect robots.txt crawl-delay 」を選択すると、Site Auditのクローラーは指示された遅延に従うようになります。
以下は、robots.txtファイル内でクロールの遅延がどのように表示されるかを示しています。
Crawl-delay: 20
当社のクローラーがお客様のウェブサイトを遅くし、robots.txtファイルにクロール遅延ディレクティブを設定していない場合、Semrushに2秒間に1つのURLをクロールするように指示できます。 このため、診断に時間がかかる可能性がありますが、診断中にウェブサイトを利用する実際のユーザーにとって、速度の問題が発生する可能性は低くなります。
URLを許可/不許可
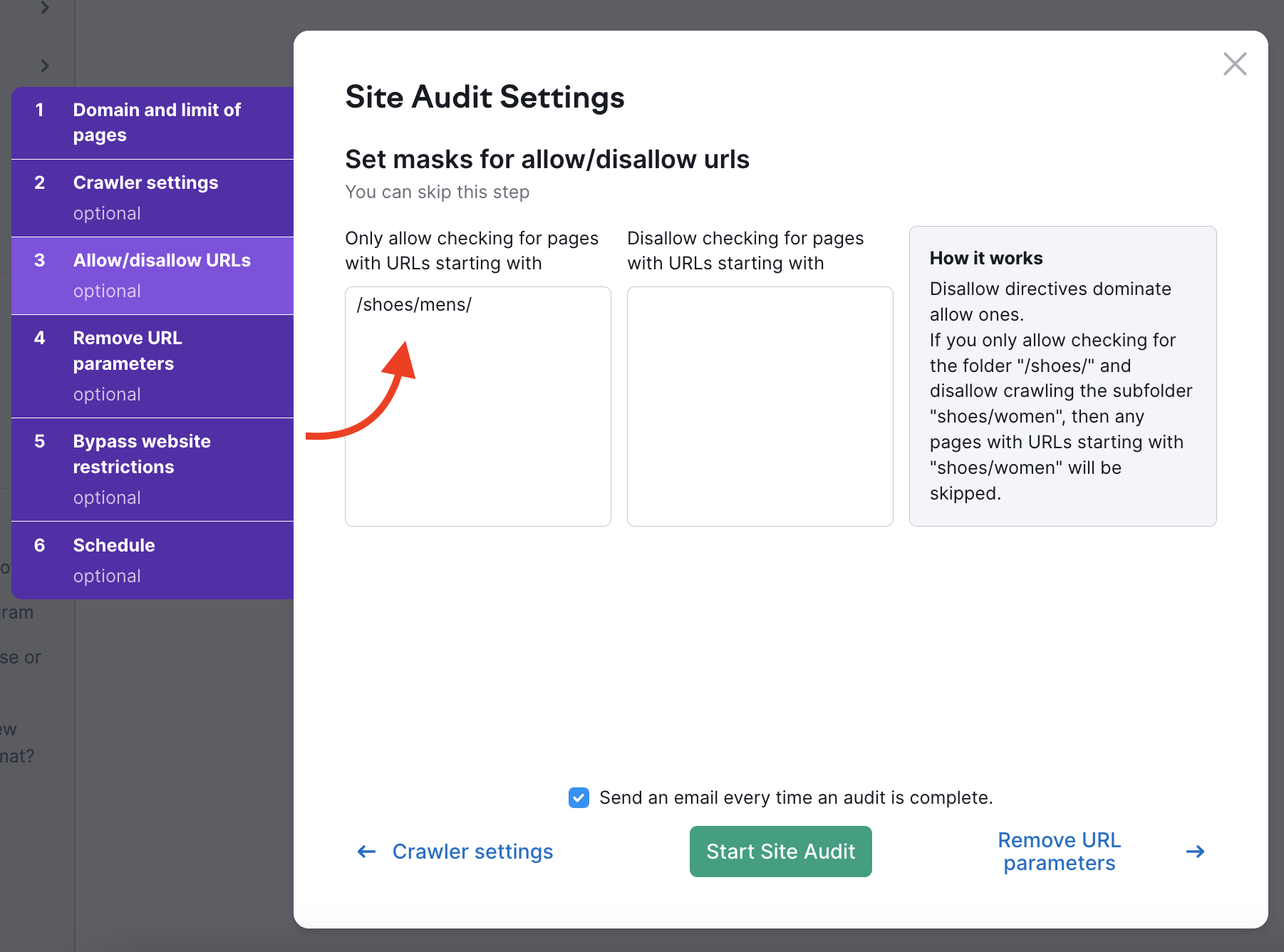
このオプションは、ウェブサイトの特定のサブフォルダをクロールまたはブロックすることを可能にします。 TLDの後にURL内のすべてを含めるようにします。 例えば、サブフォルダー http://www.example.com/shoes/mens/ をクロールしたい場合は、左側の許可ボックスに "/shoes/mens/" と入力します。
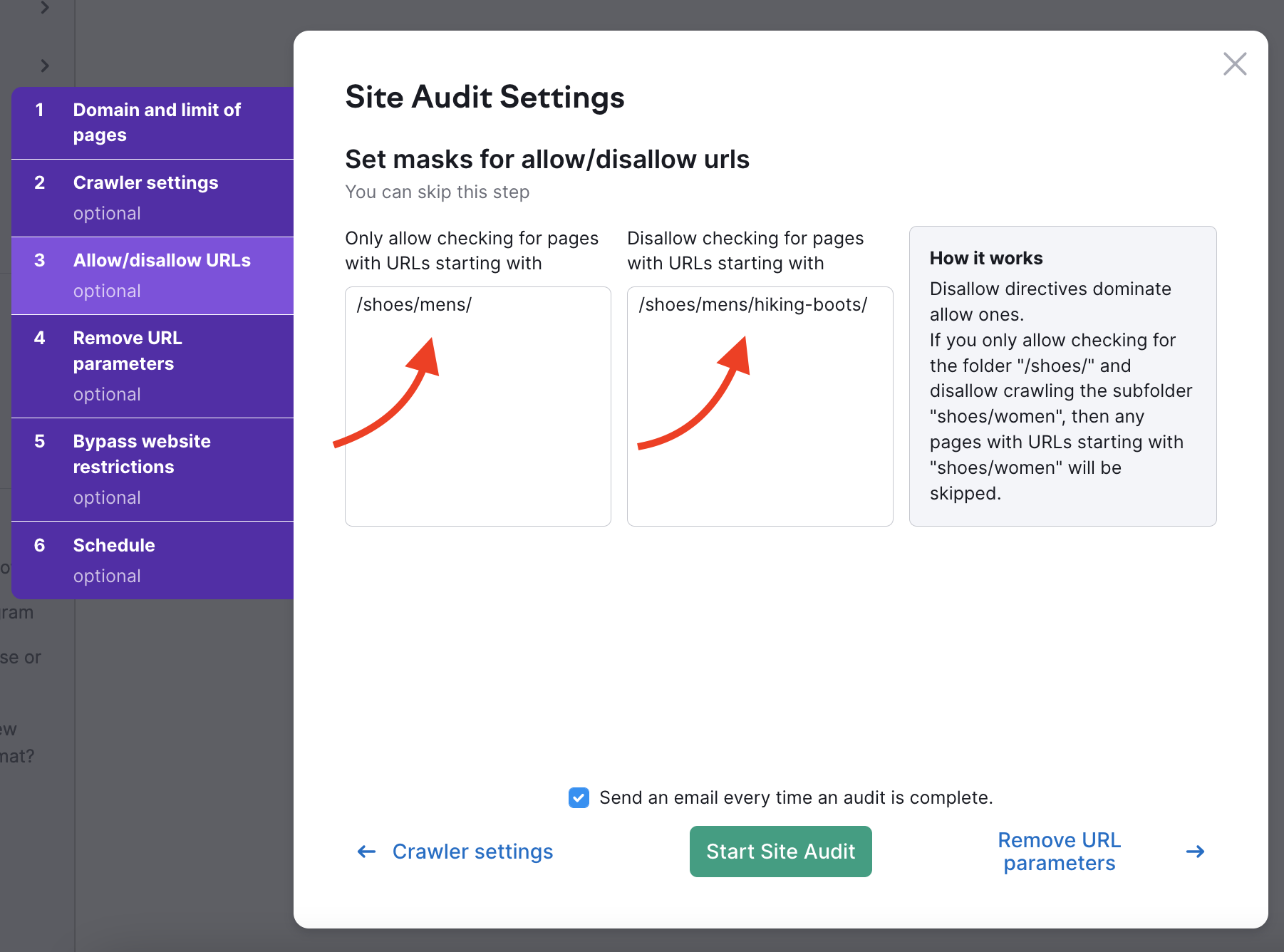
特定のサブフォルダーをクロールしないようにするには、「不許可」ボックスにサブフォルダーのパスを入力する必要があります。 例えば、メンズシューズのカテゴリをクロールし、メンズシューズの下にあるハイキングブーツのサブカテゴリを避けるには(https://example.com/shoes/mens/hiking-boots/)、不許可ボックスに /shoes/mens/hiking-boots/ と入力します。
DisallowボックスでURLの最後に/を入力し忘れた場合(例:/shoes)、Semrushは/shoes/サブフォルダ内のすべてのページ、および/shoesで始まるすべてのURL(例:www.example.com/shoes-men)をスキップします。
URLパラメータを削除する
URLパラメータ(クエリ列とも呼ばれる)は、階層的なパス構造に当てはまらないURLの要素です。 その代わり、URLの末尾に追加して、ウェブブラウザに論理的な指示を与えます。
URLパラメータは常に、? の後に パラメータ名(page、utm_mediumなど)、=が続きます。
つまり、"?page=3 "は1つのURLでスクロールの3ページ目を示すことができる簡単なURLパラメータです。
Site Auditの設定の4番目のステップでは、ウェブサイトが使用しているURLパラメータを指定し、クロール時にURLから削除できます。 これにより、Semrushが診断で同じページを2回クロールすることを避けることができます。 ボットが2つのURL(パラメータ付きとパラメータなし)を確認した場合、両方のページをクロールしてしまい、結果的にクロールの予算を無駄にしてしまう可能性があります。
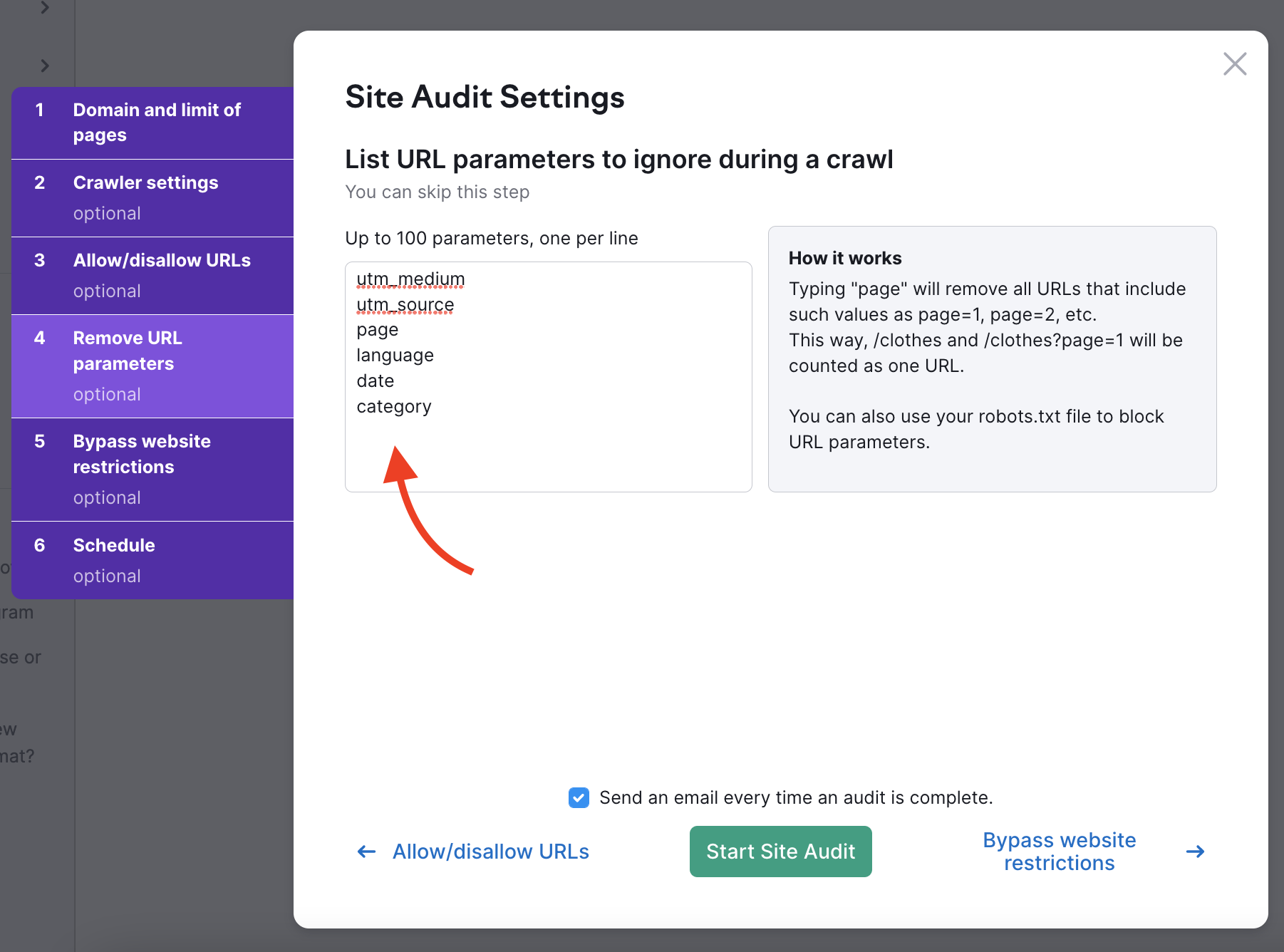
例えば、このボックスに「page」を追加すると、URLの拡張子に「page」を含むすべてのURLが削除されます。 これは、?page=1, ?page=2 などの値を持つURLとなります。 そうすれば、クロールの過程で同じページを2回クロールする(例えば、1つのURLとして「/shoes」と「/shoes/?page=1」の両方をクロールする)ことを避けることができます。
URLパラメータの一般的な用途は、ページ、言語、サブカテゴリーなどです。 このタイプのパラメータは、製品や情報のカタログを大量に持つウェブサイトに有効です。 もう一つの一般的なURLパラメータタイプはUTMsです。これはマーケティングキャンペーンからのクリックやトラフィックを追跡するために使用されます。
ウェブサイトのパラメータの正確なリストは、Google Search Consoleで確認できます。 左側のメニューから、「クロール - URL パラメータ」を探します。 また、ウィンドウ内の「仕組み」の段落の下に、Google Search ConsoleのウェブサイトのURLパラメータ一覧に移動するリンクがあります。
すでにプロジェクトが設定されており、設定を変更したい場合は、設定ギアを使って変更できます。

「マスク」と「削除されたパラメータ」のオプションを選択することで、上記と同様の指示を行います。
ウェブサイト制限の回避
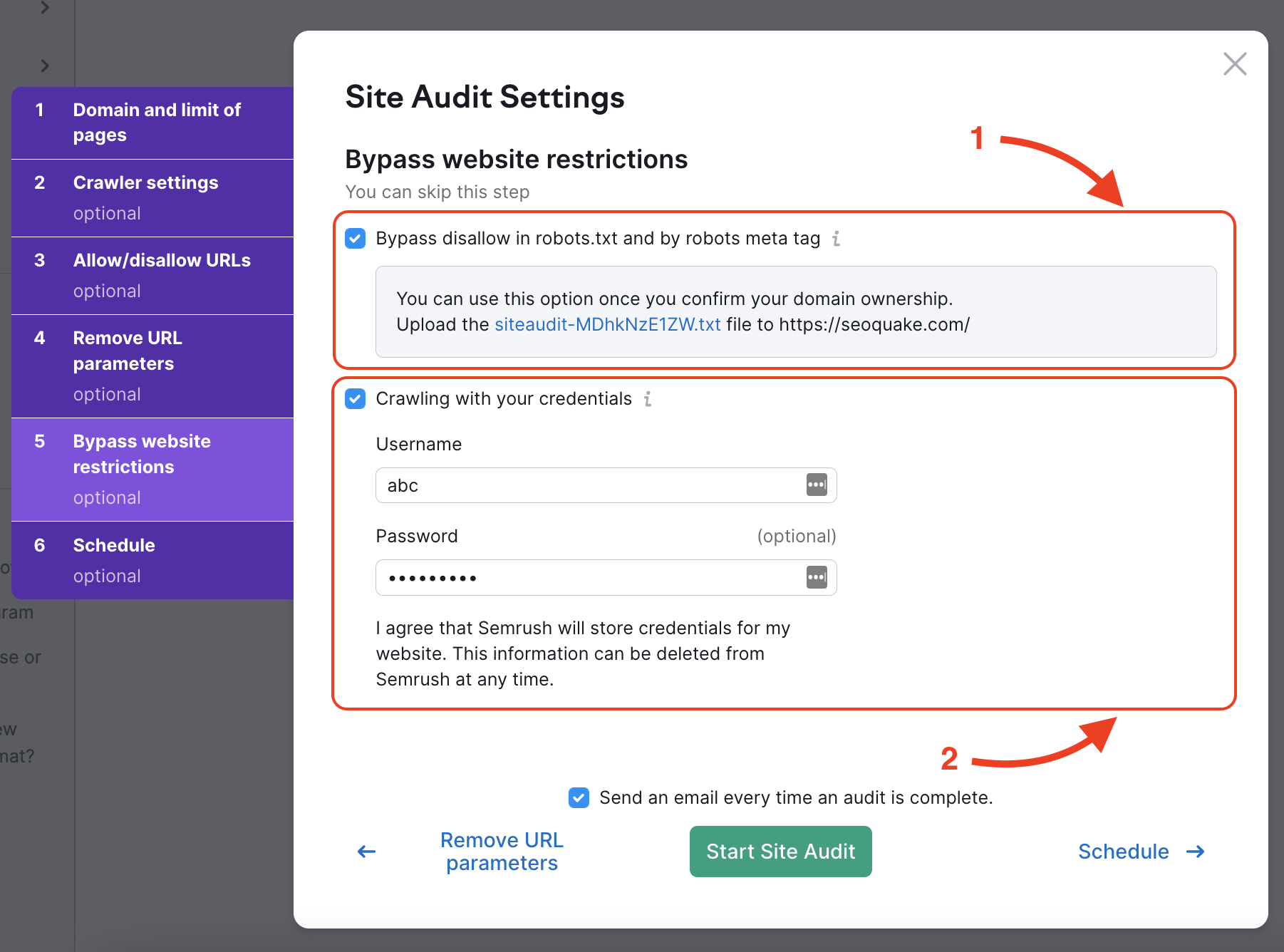
本番環境前のウェブサイトや基本アクセス認証で隠されているウェブサイトを診断するには、手順5で2つのオプションがあります。
- Robots.txtとrobots metaタグの不許可を回避する
- パスワードで保護された領域を回避するために、認証情報を使ってクロールします。
Robots.txtまたはmetaタグ(通常、これはウェブサイトの<head>タグにあります)でdisallowコマンドを回避したい場合、Semrushが提供する.txtファイルをウェブサイトのメインフォルダにアップロードする必要があります。
このファイルは、例えばGSC検証用ファイルと同じように、ウェブサイトのメインフォルダに直接アップロードできます。 この処理により、お客様のウェブサイトの所有権が確認され、サイトのクロールが可能になります。
ファイルのアップロードが完了したら、Site Auditを開始し、結果を収集できます。
認証情報を使ってクロールする場合は、ウェブサイトの隠されている部分にアクセスするために使用するユーザー名とパスワードを入力するだけです。 その後、当社のボットがお客様のログイン情報を使って隠れた部分にアクセスし、診断結果を提供します。
スケジュール
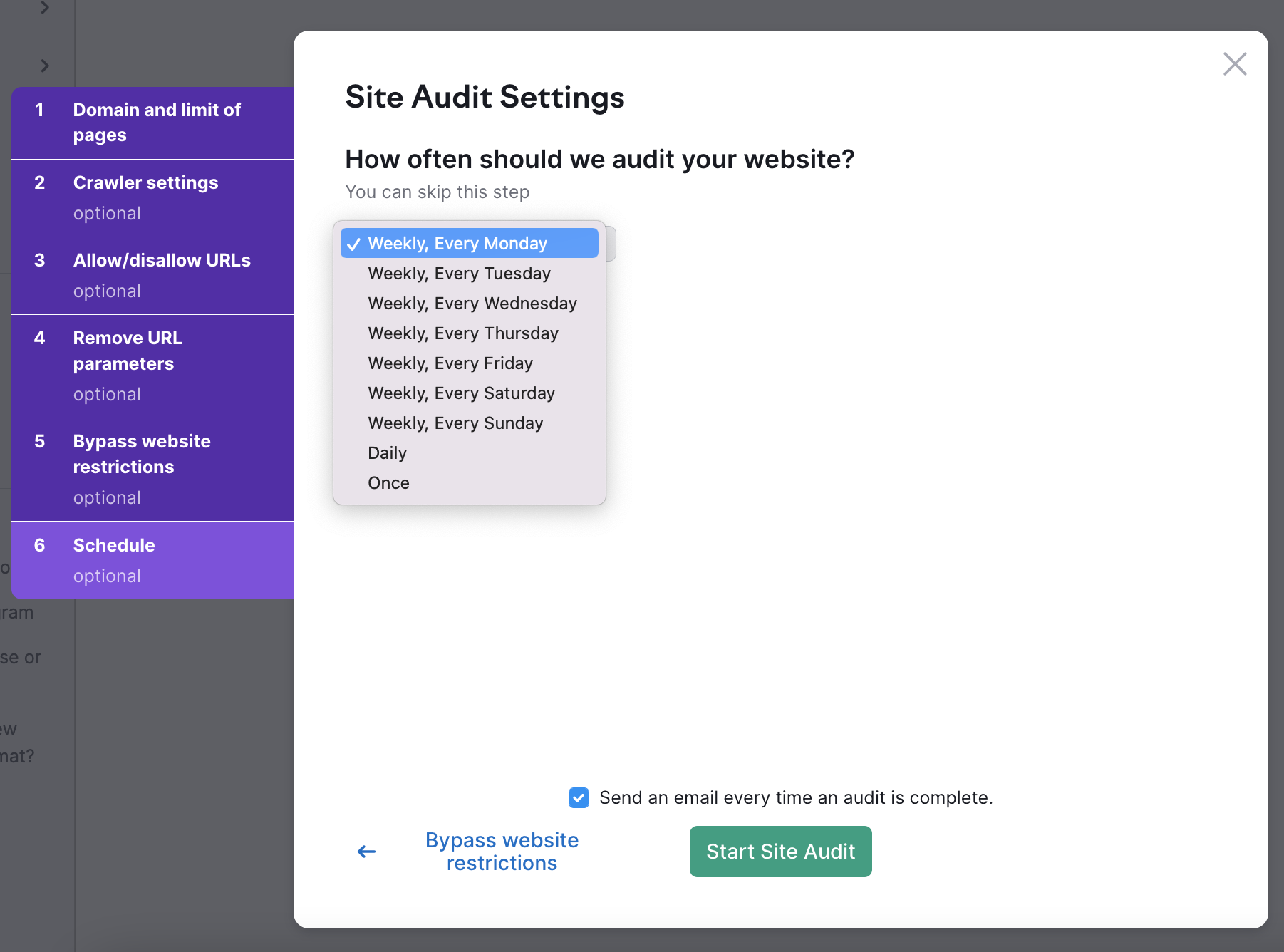
最後に、ウェブサイトを自動的に診断する頻度を選択します。 オプションは、以下の通りです。
- 週ごと(好きな曜日を選択可能)
- 毎日
- 一度
プロジェクト内では、いつでも都合の良い時に診断を再実行できます。
希望の設定がすべて完了したら、「Site Auditを開始」を選択します。
トラブルシューティング
「診断ドメインが失敗しました」ダイアログが表示された場合、当社のサイト診断用クローラーがお客様のサーバーでブロックされていないことを確認します。 適切なクロールを行うために、サイト診断トラブルシューティングの手順に従って、当社のボットをホワイトリストに登録します。
または、クロールが失敗したときに生成されるログファイルをダウンロードして、ウェブマスターに提供することで、状況を分析し、クロールがブロックされた理由を見つけることを試みることができます。 ウェブサイトのログファイルを自分で分析する方法が必要な場合は、Log File Analyzerツール にログファイルをアップロードします。
Google AnalyticsとSite Auditを連携させる
設定ウィザードの完了後、Google Analyticsアカウントを接続すると、トップビューページに関する問題を含めることができるようになります。
Site Auditを実行しても問題が解決しない場合は、Site Auditのトラブルシューティングをお試しいただくか、サポートチームにお問い合わせください。